It was recently brought to my attention that a bunch of so called "Spurious Correlations" have been identified (http://www.tylervigen.com/spurious-correlations). In addition to being entertaining, these highly correlated relations between two clearly unrelated variables are interesting to me from a mathematical point of view. Primarily, I am curious as to just how probable this sort of spurious correlation is as well when I should be wary of strong correlations.
I believe the fundamental principles to getting strong correlation between random data sets is having a small sample size and an equal domain (e.g. [0,1] in rescaled units). When these two effects are implemented, the probability of realizing a strong correlation between random variables becomes very realistic. All one would need is access to lots of data sets to test for correlation. Thus, I will calculate, on average, how many random data sets would you expect to analyze before finding a strong correlation.
The following example is actually a visually convincing correlation. However, there is obviously not a relationship between the age of miss America and the number of murders by hot objects... or is there? We will use this as the test case in the analysis that follows.
I believe the fundamental principles to getting strong correlation between random data sets is having a small sample size and an equal domain (e.g. [0,1] in rescaled units). When these two effects are implemented, the probability of realizing a strong correlation between random variables becomes very realistic. All one would need is access to lots of data sets to test for correlation. Thus, I will calculate, on average, how many random data sets would you expect to analyze before finding a strong correlation.
The following example is actually a visually convincing correlation. However, there is obviously not a relationship between the age of miss America and the number of murders by hot objects... or is there? We will use this as the test case in the analysis that follows.
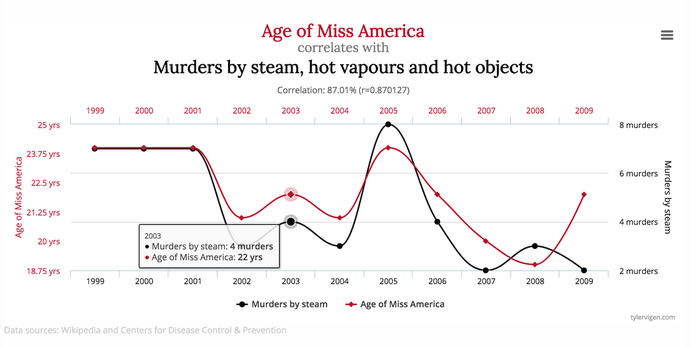
The primary question we want to answer is what the probability of realizing a high correlation (87%) given a small sample (N =11) of two random variables on the same domain.
We could answer this question analytically in a straightforward manner involving random variables, but instead I will simulate it numerically, which is much more mindless.
If we randomly generate two data sets of 11 points each, we can calculate the correlation coefficient between them and repeat this calculation many times (10^6) to see how rare a correlation greater than 87% is. The results are shown below with a green line indicating where on the distribution the desired correlation falls.
We could answer this question analytically in a straightforward manner involving random variables, but instead I will simulate it numerically, which is much more mindless.
If we randomly generate two data sets of 11 points each, we can calculate the correlation coefficient between them and repeat this calculation many times (10^6) to see how rare a correlation greater than 87% is. The results are shown below with a green line indicating where on the distribution the desired correlation falls.
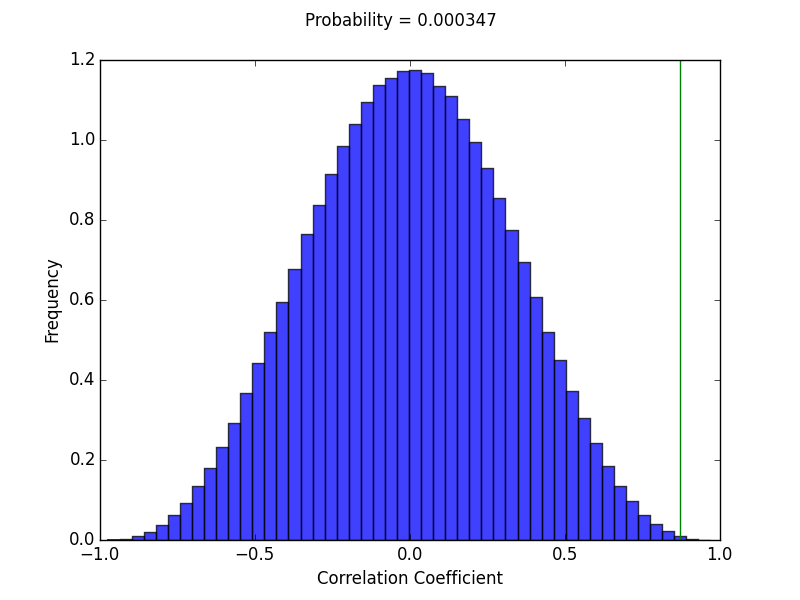
On average, one would have to analyze less than 3000 data sets to find a correlation greater than or equal to 87%
So that's that. If you have small data sets and you rescale them to be on the same domain you can easily find spurious correlations if you have enough data sets to go through.
The other question is how correlation scales with the number of data points you keep. If we assume that our variables are indeed random (i.e. uncorrelated), then we would expect the chances of finding a correlation over 87% to diminish as we increase the size of our data set. We can run this simulation in a similar fashion, except this time we generate 10^6 trials for a given N, calculate the number with a correlation coefficient over 87% and repeat for N+1, N+2, etc. to see how much less likely the correlation becomes. The results are shown below.
The other question is how correlation scales with the number of data points you keep. If we assume that our variables are indeed random (i.e. uncorrelated), then we would expect the chances of finding a correlation over 87% to diminish as we increase the size of our data set. We can run this simulation in a similar fashion, except this time we generate 10^6 trials for a given N, calculate the number with a correlation coefficient over 87% and repeat for N+1, N+2, etc. to see how much less likely the correlation becomes. The results are shown below.
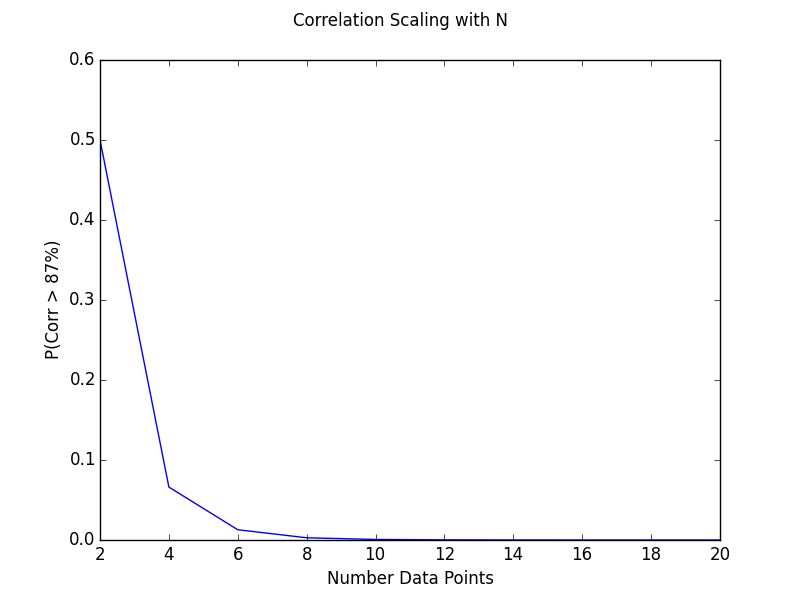
The take home message here is for data sets of 10 points or less the probability of spurious correlations is certainly not negligible, especially when considering large ensembles of data.
 RSS Feed
RSS Feed
