A while back, I was on a west coast road trip with a friend and with hours to kill we found ourselves listening to the same Spotify playlist (this one) over and over. However, the weird thing about this is we aren't actually sure we ever made it through the entire playlist. Since we were not using Spotify Premium, the songs that we heard were randomly drawn from the playlist. Thus, even though we may have listened to 200 songs, its possible that we didn't hear every song once - instead we just heard the worst song 150 times.
The question, therefore, is how many songs should one expect to listen to before hearing every song in a random playlist once?
The question, therefore, is how many songs should one expect to listen to before hearing every song in a random playlist once?
Method 1 - Stirling Numbers
More generally, this is a question regarding randomly sampling with replacement, but to begin, we can consider the Spotify question.
If the playlist were only four songs, then it is likely that we should expect to complete it in a relatively short amount of time (perhaps a dozen songs or so). The expected number of songs to complete a playlist of n songs is given by the average <L> :
If the playlist were only four songs, then it is likely that we should expect to complete it in a relatively short amount of time (perhaps a dozen songs or so). The expected number of songs to complete a playlist of n songs is given by the average <L> :
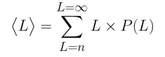
Thus, to calculate the number of songs we would expect before playlist completion (<L>), we need to know the probability P(L) that an n song playlist ends after exactly L songs.
If we were asking the question "what is the probability that a list of L songs contains every song from an n song playlist", we could easily answer this using Stirling Numbers of the second kind S(L,n), because n!*S(L,n) is the number of ways to split up L songs into n labeled groups such that no group is empty (see case 7 in this article by John Cook). For example, using a Stirling Number generator, we can calculate 4!*S(7,4) = 4!*350 = 8400 ; this means that there are 8400 different lists or orderings of length 7 that contain all 4 unique songs from the playlist. Some examples would be 1234444, 33311224, 1213411, etc. So to calculate the probability we would just divide n!*S(L,n) by the total number of lists (not necessarily containing all n songs) which is n^L (since each of the L locations has n possible songs). However, in order to calculate <L>, we need the probability that an n song playlist ends after exactly L songs, which is a slightly different question.
Requiring that the playlist ends after exactly L songs implies that the last song in the list (the Lth song) has not been heard before! If the song were not unique, then it would be a repeat of a previous song, which means either you've heard the entire playlist already, or you haven't heard it all yet. In the 7 song lists above, 1234444 really ended at the 4th song rather than the 7th (since every spot after 4 was a repeat), whereas 33311224 really ended at the 7th song (before then not every song had been heard). Thus, we must insist that the last song is unique, and it is the last unique song required to complete the playlist.
Thus, there are three steps to correctly calculate the number of ways that an n song playlist ends after exactly L songs:
1. Choose one of the n songs to be last
2. For a given choice count how many ways there are to hear the all other (n-1) songs in (L-1) spots
3. Repeat for each of the n possible last songs
The second step is given by (n-1)!*S(L-1,n-1) since we are asking how many ways are there to map (n-1) songs to (L-1) spots. So for a given last song, there are n!*S(L-1,n-1) lists that end with that song, and since there are n possible last songs there are n*(n-1)!*S(L-1,n-1) = n!*S(L-1,n-1) total ways to end an n song playlist in exactly L songs. Therefore, the probability P(L) is:
If we were asking the question "what is the probability that a list of L songs contains every song from an n song playlist", we could easily answer this using Stirling Numbers of the second kind S(L,n), because n!*S(L,n) is the number of ways to split up L songs into n labeled groups such that no group is empty (see case 7 in this article by John Cook). For example, using a Stirling Number generator, we can calculate 4!*S(7,4) = 4!*350 = 8400 ; this means that there are 8400 different lists or orderings of length 7 that contain all 4 unique songs from the playlist. Some examples would be 1234444, 33311224, 1213411, etc. So to calculate the probability we would just divide n!*S(L,n) by the total number of lists (not necessarily containing all n songs) which is n^L (since each of the L locations has n possible songs). However, in order to calculate <L>, we need the probability that an n song playlist ends after exactly L songs, which is a slightly different question.
Requiring that the playlist ends after exactly L songs implies that the last song in the list (the Lth song) has not been heard before! If the song were not unique, then it would be a repeat of a previous song, which means either you've heard the entire playlist already, or you haven't heard it all yet. In the 7 song lists above, 1234444 really ended at the 4th song rather than the 7th (since every spot after 4 was a repeat), whereas 33311224 really ended at the 7th song (before then not every song had been heard). Thus, we must insist that the last song is unique, and it is the last unique song required to complete the playlist.
Thus, there are three steps to correctly calculate the number of ways that an n song playlist ends after exactly L songs:
1. Choose one of the n songs to be last
2. For a given choice count how many ways there are to hear the all other (n-1) songs in (L-1) spots
3. Repeat for each of the n possible last songs
The second step is given by (n-1)!*S(L-1,n-1) since we are asking how many ways are there to map (n-1) songs to (L-1) spots. So for a given last song, there are n!*S(L-1,n-1) lists that end with that song, and since there are n possible last songs there are n*(n-1)!*S(L-1,n-1) = n!*S(L-1,n-1) total ways to end an n song playlist in exactly L songs. Therefore, the probability P(L) is:
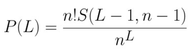
Using a computer, we can plot this function for a variety of playlist lengths n and see what the probability of the playlist ending after exactly L songs looks like (see below).
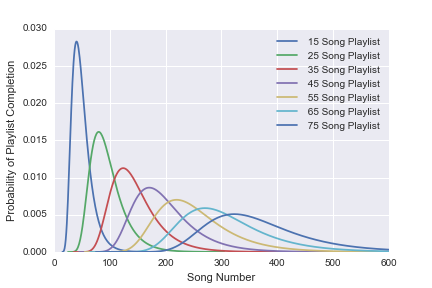
And, now that we have P(L), we can finally calculate the expected number of songs before completion <L> as a function of the playlist length n. The results are shown below:
What really surprised me about these results is how well a linear fit matches the theory, because the full definition for <L> (using the definition for Stirling Numbers) as a function of n looks as follows:
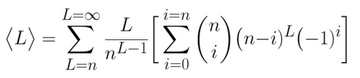
Yet the simple linear expression:
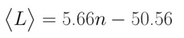
can capture 99.8% of the variation in <L> due to n! Whether or not there exists a simple linear approximation for the definition of <L> seems like an interesting question. (UPDATE: see method 2)
Regardless, we can now answer the question of how many songs we would expect to play before hearing every song in the a random playlist once. Plugging in n=35 to the linear expression yields:
Regardless, we can now answer the question of how many songs we would expect to play before hearing every song in the a random playlist once. Plugging in n=35 to the linear expression yields:
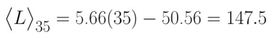
So we would expect to listen to close to 148 songs before hearing each song in a 35 song playlist once. At 4 minutes a song, this means we would have to listen for roughly 10 hours, on average, before hearing each song in a 2h20m song playlist once!!!
There are plenty of other mathematically accessible questions that could be asked within a similar framework. For example, we could ask about the probability of listening for a given amount of time without completing the playlist is. Or, the probability of a certain amount of repeats of a specific song before hearing every other song at least once. And so on and so forth. Each of these questions requires reworking the problem in a slightly different fashion, but all of them should be manageable.
At the very least, one can usually write a computer program to simulate the phenomena in question many times and count the results. For the example of the expected number of songs <L> before completing a playlist of length, we can numerically compute via brute force simulations as follows:
1) Initialize a trial
2) Draw a song from a playlist of length n
3) Repeat until every song has been drawn
4) Measure the length of this trial
5) Repeat for many trials and find the average length
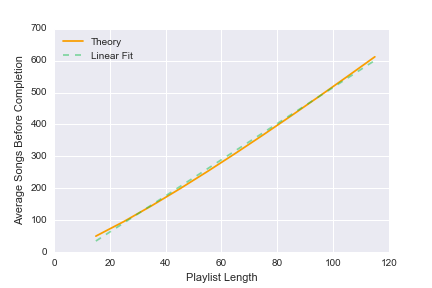
Doing this for a wide variety of n values leads to the exact same results as the theoretical predictions, as the plot below shows:
At the very least, one can usually write a computer program to simulate the phenomena in question many times and count the results. For the example of the expected number of songs <L> before completing a playlist of length, we can numerically compute via brute force simulations as follows:
1) Initialize a trial
2) Draw a song from a playlist of length n
3) Repeat until every song has been drawn
4) Measure the length of this trial
5) Repeat for many trials and find the average length
Doing this for a wide variety of n values leads to the exact same results as the theoretical predictions, as the plot below shows:
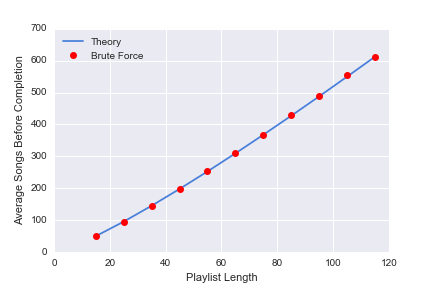
The full utility of an analytical expression is demonstrated best when a brute force approach requires too much computational power. However, for our intents and purposes, either way is accessible and both yield the same result.
The jupyter notebook (more info on jupyter here) used to implement both methods, as well as generate all plots, is attached in the form of a pdf below.
The jupyter notebook (more info on jupyter here) used to implement both methods, as well as generate all plots, is attached in the form of a pdf below.
METHOD 2 - ABSORBING MARKOV CHAIN
At last, I figured out that the way to properly address this problem is by using Markov Chains.
We let the random variable S represent the number of unique songs we have heard, so S can take values in (0,n). The probability to transition between state S_i and S_{i+1} is given by (n-i)/n where n is the total number of songs. Knowing this, we can calculate the expected number of songs we need to hit the absorbing state n given that we start in state i; we will denote this expectation value k_i. To do so, we set up a recursion relation given by:
k_i = 1 + (n-i)/n*k_{i+1} + i/n*k_i
The recursion can be understood as follows: Given that we are in state i, the expected number of steps before hitting state n is one plus the expected number of steps to hit state n from state {i+1} weighted by the probability to reach state {i+1}. However, we must also account for the probability to remain in state i, in which case we have drawn a song without actually reaching state {i+1} - this is the last term on the right hand side.
The recursion relation holds for all i in (0,n-1), and, since state n is absorbing, the expected number of steps to reach state n from state n is simply 0. Thus, we have k_n = 0 as the necessary boundary condition for our recursion relation.
We can solve the recursion relation through a variety of means, but the easiest, perhaps, is simply to take i=0 and write out the first few terms. For example, taking i=0 and n=5, we find:
k_0 = 5(1/5+2/5+3/5+4/5 + 5/5)
This simple formula holds quite generally and we can write k_0 in a closed form as:
k_0 = n*H(n)
where H(n) is the harmonic number n given by the sum from i=1 to n of 1/i (e.g. H(5) = 1/5+2/5+3/5+4/5+5/5). Harmonic numbers can easily be looked up for any reasonable value of n. Moreover, the Markov Property of this system says that S_{i+1} is completely independent of S_{i}. This means that, since the system is memoryless, we can easily take any state i and call it state 0. This allows us to solve for the expected number of steps to reach state n in terms of any initial starting location i (bounded by (0,n)):
k_i = (n-i)*H(n-i)
This is saying that the expected number of songs to complete a random playlist of length n given that you start in state i is the same as the number of songs to complete a playlist of (n-i) songs, which makes sense.
We can express H(n) in terms of more familiar functions using the asymptotic expansion:
H(n) ~ ln(n) + gamma + 1/(2n) - 1/(12*n^2) + 1/(120*n^4) - ...
where gamma is a constant known as the "Euler-Mascheroni Constant" and takes the value gamma = 0.5772.
This means that for relatively large n, we have:
k_0 ~ n*ln(n) + n*gamma+1/2 + [O(1/n^3)]
using this formula for a 35 song playlist yields:
k_0 (35) = 145.14
This answer can be double checked against the brute force calculations, which predict k_0(35) = 145.1; thus, we see that the Markov Method laid out about does indeed yield the correct results.
We let the random variable S represent the number of unique songs we have heard, so S can take values in (0,n). The probability to transition between state S_i and S_{i+1} is given by (n-i)/n where n is the total number of songs. Knowing this, we can calculate the expected number of songs we need to hit the absorbing state n given that we start in state i; we will denote this expectation value k_i. To do so, we set up a recursion relation given by:
k_i = 1 + (n-i)/n*k_{i+1} + i/n*k_i
The recursion can be understood as follows: Given that we are in state i, the expected number of steps before hitting state n is one plus the expected number of steps to hit state n from state {i+1} weighted by the probability to reach state {i+1}. However, we must also account for the probability to remain in state i, in which case we have drawn a song without actually reaching state {i+1} - this is the last term on the right hand side.
The recursion relation holds for all i in (0,n-1), and, since state n is absorbing, the expected number of steps to reach state n from state n is simply 0. Thus, we have k_n = 0 as the necessary boundary condition for our recursion relation.
We can solve the recursion relation through a variety of means, but the easiest, perhaps, is simply to take i=0 and write out the first few terms. For example, taking i=0 and n=5, we find:
k_0 = 5(1/5+2/5+3/5+4/5 + 5/5)
This simple formula holds quite generally and we can write k_0 in a closed form as:
k_0 = n*H(n)
where H(n) is the harmonic number n given by the sum from i=1 to n of 1/i (e.g. H(5) = 1/5+2/5+3/5+4/5+5/5). Harmonic numbers can easily be looked up for any reasonable value of n. Moreover, the Markov Property of this system says that S_{i+1} is completely independent of S_{i}. This means that, since the system is memoryless, we can easily take any state i and call it state 0. This allows us to solve for the expected number of steps to reach state n in terms of any initial starting location i (bounded by (0,n)):
k_i = (n-i)*H(n-i)
This is saying that the expected number of songs to complete a random playlist of length n given that you start in state i is the same as the number of songs to complete a playlist of (n-i) songs, which makes sense.
We can express H(n) in terms of more familiar functions using the asymptotic expansion:
H(n) ~ ln(n) + gamma + 1/(2n) - 1/(12*n^2) + 1/(120*n^4) - ...
where gamma is a constant known as the "Euler-Mascheroni Constant" and takes the value gamma = 0.5772.
This means that for relatively large n, we have:
k_0 ~ n*ln(n) + n*gamma+1/2 + [O(1/n^3)]
using this formula for a 35 song playlist yields:
k_0 (35) = 145.14
This answer can be double checked against the brute force calculations, which predict k_0(35) = 145.1; thus, we see that the Markov Method laid out about does indeed yield the correct results.
 RSS Feed
RSS Feed
